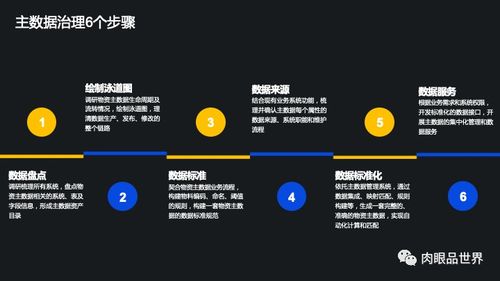
随着大数据时代的到来,数据量呈现爆炸式增长,传统的数据处理技术面临前所未有的挑战。SPSS(Statistical Package for the Social Sciences)作为一种成熟的统计分析软件,凭借其强大的统计建模和可视化功能,被广泛应用于大数据处理领域。本文将探讨SPSS如何融入大数据处理流程,分析其优势与局限,并提出有效的应用策略。
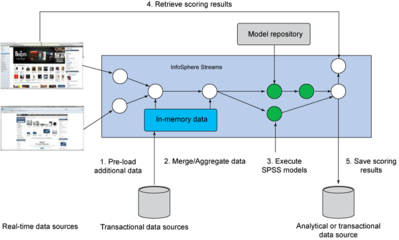
SPSS在大数据处理中发挥着重要作用。其核心优势在于提供直观的用户界面和丰富的统计方法,如描述性统计、回归分析、聚类分析和因子分析等。用户可以通过SPSS Modeler等工具处理大规模数据集,结合数据挖掘技术识别隐藏模式。例如,在商业智能领域,企业利用SPSS分析客户行为数据,优化营销策略;在医疗健康领域,研究人员处理海量临床数据,预测疾病风险。SPSS的可视化功能还能将复杂数据转化为图表,帮助决策者快速理解结果。
SPSS在处理超大规模数据时存在一定局限。由于其最初设计面向中小型数据集,当数据量达到TB或PB级别时,可能面临性能瓶颈,如内存不足或处理速度慢。为此,用户需结合其他大数据技术,如Hadoop或Spark,进行数据预处理和分布式计算。例如,可以先用Hadoop进行数据清洗和聚合,再将结果导入SPSS进行深入分析。这种混合模式既能发挥SPSS的统计分析优势,又能利用大数据平台的高效处理能力。
为优化SPSS在大数据中的应用,建议采取以下策略:一是加强数据预处理,通过抽样或降维技术减少数据规模;二是利用SPSS的扩展功能,如与Python或R集成,实现自定义分析脚本;三是注重数据安全与隐私保护,确保合规性。未来,随着SPSS不断升级,其与云计算的结合将进一步拓展大数据分析的可能性。
SPSS作为一款经典的分析工具,在大数据时代仍具有重要价值。通过合理整合其他技术,它能有效提升数据处理的效率与深度,为各行业提供有力的决策支持。