大数据分析挖掘已成为驱动现代商业决策与科学发现的核心引擎,而数据处理技术则是其坚实的地基。本课程旨在系统性地传授大数据处理的关键技术与实战方法,为学员构建从数据采集到价值提取的完整能力链条。
一、 课程核心要点
- 核心理念建立:深刻理解大数据4V特性(Volume, Velocity, Variety, Veracity)对数据处理提出的挑战与要求,树立“数据质量是分析生命线”的工程化思维。
- 技术栈全景掌握:系统学习批处理与流处理两大范式,掌握以Hadoop、Spark、Flink为代表的核心开源生态工具。
- 全流程技能覆盖:从数据采集与集成、存储与管理、清洗与转换,到最终的聚合与准备,掌握每个环节的主流技术与最佳实践。
- 性能与优化意识:理解分布式计算原理,学习数据倾斜处理、存储格式优化、计算资源调优等关键性能提升技术。
- 实战能力培养:通过基于真实场景或高仿真数据集的项目练习,强化学员解决复杂数据问题的综合能力。
二、 详细课程大纲
模块一:大数据处理基础与生态概述
- 大数据概念、挑战与典型应用场景
- 分布式系统基础概念(CAP定理、容错、伸缩性)
- Hadoop生态系统简介(HDFS, YARN)
- 数据处理范式:批处理 vs. 流处理 vs. 交互式查询
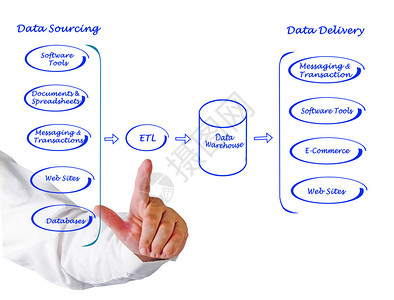
模块二:大数据采集与集成
- 数据来源:日志文件、数据库、传感器、第三方API等
- 批量采集工具:Sqoop, DataX
- 实时采集工具:Flume, Kafka(作为消息队列与数据管道)
- 数据集成策略与数据湖/仓库入口建设
模块三:分布式存储与数据管理
- HDFS原理、架构与操作
- 列式存储:HBase原理与基本使用
- 数据仓库概念:Hive表设计、分区与分桶
- 云原生存储简介(如AWS S3, Azure Blob Storage)
模块四:批处理核心技术 - Apache Spark
- Spark核心概念:RDD、DataFrame/Dataset
- Spark SQL:结构化数据查询与处理
- Spark Core:Transformation与Action操作,宽窄依赖与执行计划
- 性能调优:内存管理、分区策略、广播变量与累加器
模块五:流处理核心技术
- 流处理概念与架构(Lambda/Kappa架构)
- Apache Spark Streaming:微批处理模型
- Apache Flink:真正的流处理引擎,时间语义与窗口操作
- Kafka Streams:轻量级流处理库应用
模块六:数据清洗、转换与质量保障
- 数据清洗:处理缺失值、异常值、重复值
- 数据转换:规范化、标准化、编码、特征工程基础
- 使用Spark、Pandas等工具进行数据清洗与转换实战
- 数据质量维度与监控:准确性、完整性、一致性、时效性
模块七:数据处理工作流与调度
- 工作流编排工具:Apache Airflow, Oozie
- 任务依赖管理、定时调度与监控告警
- 构建端到端、可维护的数据处理流水线
模块八:云平台数据处理实战与趋势
- 主流云平台(AWS EMR, Azure HDInsight, Google Dataproc)上的数据处理服务
- 无服务器数据处理(如AWS Glue, Azure Data Factory)
- 当前趋势探讨:湖仓一体(Lakehouse)、实时数仓、数据处理自动化
三、 教学方法与预期成果
课程将采用“理论讲解-演示-实验-项目”四步法。学员在完成课程后,将能够:
- 独立设计并实施针对特定业务需求的大数据处理方案;
- 熟练运用Spark、Flink等核心框架进行批量和实时数据处理开发;
- 构建健壮、高效、可维护的数据管道,为上层分析与挖掘提供高质量数据底座;
- 具备解决实际生产中常见数据问题(如性能瓶颈、数据倾斜)的能力。
数据处理技术是大数据价值炼金术的第一步。本课程大纲旨在构建一个既全面又深入的技能体系,帮助学员筑牢根基,从容应对海量数据的挑战,并为其在大数据分析与数据科学领域的深入发展铺平道路。