在当今数据驱动的时代,高效、可靠地处理海量信息已成为企业竞争的核心能力。本文将系统性地探讨大数据处理的基础架构、两种核心数据处理模式(OLTP与OLAP)的区别,并深入解析以数据库、Hadoop、Spark、Hive及Flink为代表的现代大数据技术生态。
一、 大数据处理的基础架构
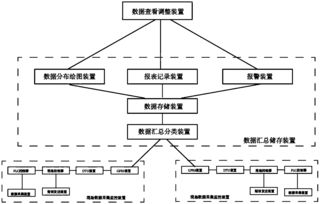
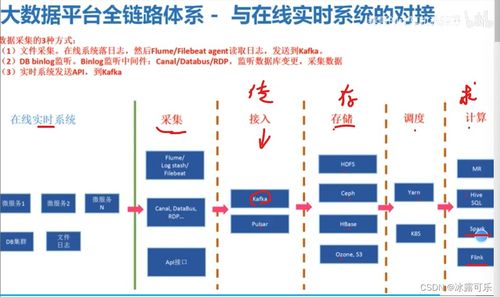
大数据基础架构是一个复杂的分布式系统集合,其核心目标在于实现对海量、多样、高速(即大数据的“3V”特性:Volume, Variety, Velocity)数据的存储、处理和分析。一个典型的大数据技术栈通常包含以下层级:
- 数据采集与集成层:负责从各种来源(如日志、传感器、数据库、应用程序)实时或批量地采集数据。常用工具有Flume、Kafka、Sqoop等。
- 数据存储层:提供海量数据的持久化存储。这既包括传统的结构化数据存储(如关系型数据库),也包括为大规模非结构化或半结构化数据设计的分布式文件系统(如HDFS)和NoSQL数据库(如HBase、Cassandra)。
- 计算与处理层:这是大数据架构的核心,负责对存储层的数据进行各种计算。它包括批处理框架(如MapReduce、Spark Core)、流处理框架(如Flink、Storm、Spark Streaming)以及交互式查询引擎(如Impala、Presto)。
- 资源管理与协调层:为上层应用提供统一的资源调度、作业管理和集群协调服务。YARN(Yet Another Resource Negotiator)是Hadoop生态中的核心资源管理器,而ZooKeeper则提供分布式协调服务。
- 数据查询与分析层:为用户和应用程序提供访问和处理数据的接口,包括SQL-on-Hadoop工具(如Hive)、数据仓库、OLAP引擎以及各类机器学习库。
- 数据治理与安全层:确保数据的质量、一致性、安全性和合规性,涉及元数据管理、数据血缘、访问控制等。
二、 OLTP与OLAP:两种关键的数据处理模式
理解联机事务处理(OLTP)与联机分析处理(OLAP)的区别,是设计数据系统的基石。
- OLTP(联机事务处理):
- 核心目标:支持日常高频的业务操作,如订单录入、银行转账、库存更新等。强调高并发、低延迟、强一致性的短小事务。
- 数据特征:处理的是最新的、细节性的操作数据,数据量相对较小但更新频繁。
- 数据库设计:通常采用规范化的关系模型(第三范式),以最大化数据一致性和减少冗余。
- 典型技术:传统的关系型数据库,如MySQL、Oracle、PostgreSQL。
- OLAP(联机分析处理):
- 核心目标:支持复杂的分析查询,为商业智能(BI)、数据分析和决策支持服务。强调大数据量的快速、复杂查询,关注数据的汇总、聚合和多维分析。
- 数据特征:处理的是历史的、聚合的、来自多个OLTP系统的数据,数据量巨大,但更新不频繁(批量加载)。
- 数据库设计:通常采用反规范化的模型,如星型模式或雪花模式,以优化查询性能。
- 典型技术:数据仓库(如Teradata)、列式存储数据库(如ClickHouse)、以及Hadoop/Spark生态中的分析工具。
核心区别:OLTP是面向“操作”的,确保每笔业务准确无误地完成;OLAP是面向“分析”的,旨在从海量历史数据中洞察规律。两者相辅相成,OLTP系统是数据的“生产者”,而OLAP系统是数据的“消费者”。
三、 现代大数据核心技术与数据处理范式
随着数据规模与复杂性激增,超越传统数据库的大数据技术栈应运而生。
- 数据库技术的演进:
- 传统关系型数据库(RDBMS)仍是OLTP场景的霸主。
- NoSQL数据库(如MongoDB、Cassandra)为应对非结构化数据、高可扩展性和灵活模式而生。
- NewSQL数据库(如Google Spanner、TiDB)试图兼顾SQL的强一致性与NoSQL的横向扩展能力。
- 云原生数据库与数据仓库(如Snowflake、Amazon Redshift)提供了弹性和易用性。
- Hadoop生态:批处理的基石
- Hadoop:一个开源分布式计算框架,核心是HDFS(分布式存储)和MapReduce(分布式计算模型)。它奠定了低成本、可扩展处理海量数据的基石,但MapReduce编程复杂且延迟高,适合离线批处理。
- Hive:构建在Hadoop之上的数据仓库工具。它将用户编写的类SQL语句(HiveQL)转换为MapReduce任务执行,大大降低了大数据分析的门槛,是早期进行大规模批处理分析的关键组件。
- Spark:统一计算引擎的革新
- Spark:一个基于内存的统一分布式计算引擎。它通过引入弹性分布式数据集(RDD)及更高级的DAG执行引擎,比MapReduce快数十到数百倍。
- 核心优势:提供了统一的编程模型(Spark Core),可同时支持批处理、交互式查询(Spark SQL)、流处理(Structured Streaming)、机器学习(MLlib)和图计算(GraphX),实现了“一栈式”解决方案。
- Flink:流处理为先的架构
- Flink:一个真正的流处理引擎,采用“流是本质,批是特例”的设计哲学。其核心是分布式数据流引擎。
- 核心优势:提供高吞吐、低延迟、Exactly-Once语义的流处理能力。其批处理被视为有界流来处理。Flink在复杂的事件驱动型应用和实时数据分析场景中表现卓越,与Spark Structured Streaming形成竞争。
四、 技术选型与融合趋势
选择合适的技术取决于具体的业务需求:
- 高频事务操作:首选OLTP关系型数据库或NewSQL。
- 离线大数据分析、历史报表:Hive on Hadoop/Spark 仍是可靠选择。
- 需要融合批处理、交互查询和机器学习的复杂分析:Spark生态是强大的一体化平台。
- 对延迟极其敏感的实时监控、实时风控、CEP(复杂事件处理):Flink是当今的业界标杆。
现代大数据架构正朝着流批一体和湖仓一体的方向演进。例如,Spark和Flink都在努力统一流和批的编程模型;而将数据湖的灵活性与数据仓库的管理性能相结合的架构,正成为企业数据平台的新标准。理解这些基础架构、模式与技术的差异与联系,是构建高效、面向未来数据系统的关键第一步。