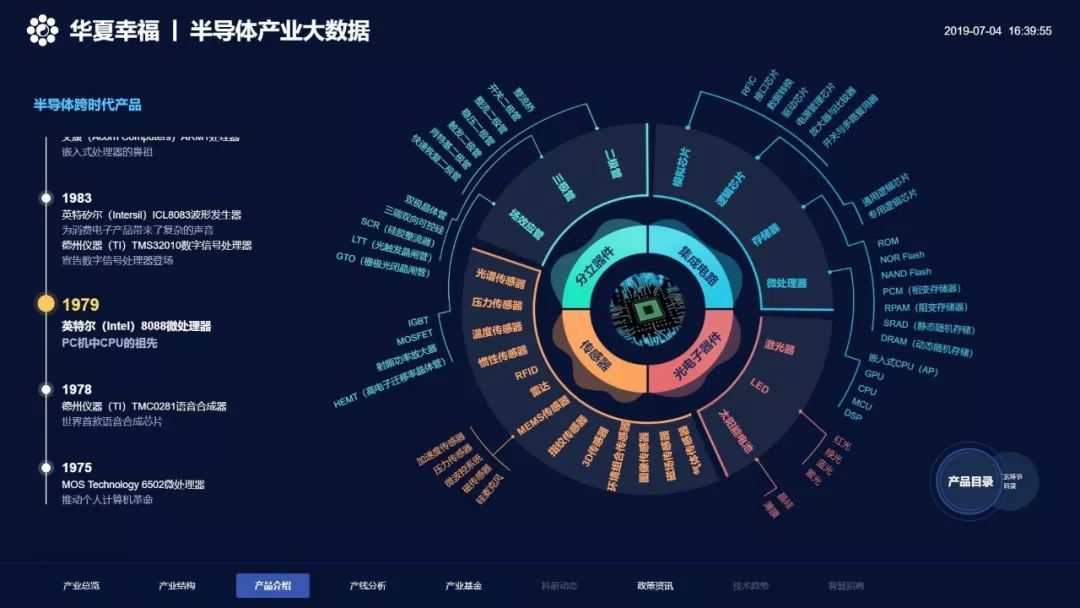
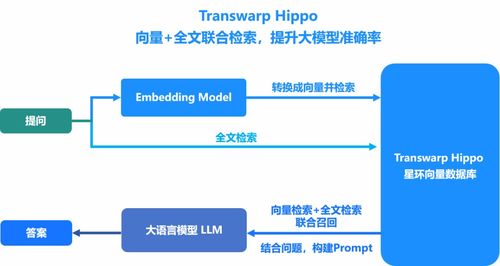
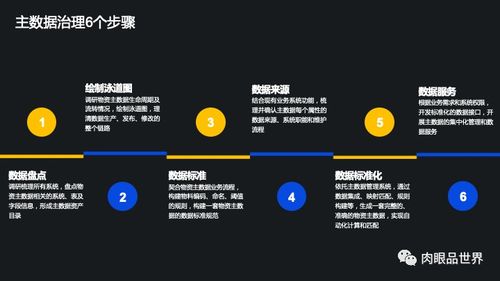
在阿里巴巴的庞大生态系统中,海量数据处理是支撑其业务增长的核心支柱。本文从阿里内部产品案例出发,深入探讨海量数据处理系统的架构设计与创新技术,帮助读者理解其背后的设计思想和实践经验。
一、海量数据处理系统的核心架构
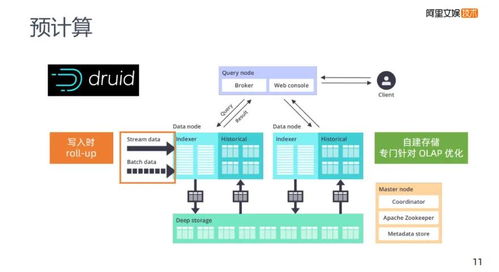
阿里的海量数据处理系统通常采用分层架构,从数据采集、存储、计算到应用,每层都融入了高度的可扩展性和容错性。以阿里云MaxCompute(原ODPS)为例,其架构包括:
- 数据接入层:通过DataHub、LogHub等组件,实现多源数据的实时采集与传输。
- 存储层:基于分布式文件系统(如盘古)和对象存储(如OSS),确保数据的高可靠与低成本存储。
- 计算层:依托MapReduce、Spark和Flink等引擎,支持批处理与流式计算的统一。
- 调度与资源管理层:采用Fuxi调度系统,实现任务的智能分配和资源隔离。
- 应用层:通过DataWorks等工具,为业务方提供数据开发、治理和可视化服务。
这种分层设计不仅提升了系统的模块化程度,还使得各层可以根据业务需求独立扩展,有效应对数据量从TB到EB级的增长。
二、创新数据处理技术的应用
在技术层面,阿里引入了多项创新,以优化性能、降低成本并提高数据处理的智能化水平。
1. 实时与离线一体化计算:
阿里通过Blink(基于Flink的流计算引擎)和MaxCompute的融合,实现了流批一体的数据处理模式。例如,在双11大促中,系统能够同时处理实时交易数据和离线分析任务,确保业务决策的及时性与准确性。
2. 智能数据压缩与存储优化:
针对海量数据存储成本高的问题,阿里研发了自适应压缩算法,根据数据特征动态选择压缩策略,平均降低存储空间30%以上。利用分层存储技术,将冷热数据分别存储于高性能和低成本介质中。
3. 数据湖与数据仓库的融合:
阿里内部产品如Data Lake Formation和AnalyticDB,实现了数据湖与数据仓库的无缝集成。用户可以在数据湖中自由探索原始数据,并通过数据仓库进行高效分析,兼顾灵活性与性能。
4. AI驱动的数据治理:
借助机器学习技术,阿里构建了智能数据血缘和质量监控系统。例如,DataWorks内置的AI助手可以自动识别数据异常、推荐优化策略,减少人工干预,提升数据可靠性。
5. 边缘计算与云边协同:
在物联网场景下,阿里将数据处理能力下沉至边缘节点,通过Link IoT Edge等产品实现本地实时处理,并结合云端进行深度分析,降低了网络延迟与带宽消耗。
三、实践经验与挑战
尽管阿里的海量数据处理系统在架构和技术上表现卓越,但在实践中仍面临诸多挑战:
- 数据安全与合规:随着数据量的激增,如何确保数据隐私和满足全球法规(如GDPR)成为关键问题。阿里通过加密、脱敏和权限管控等多层防护机制应对。
- 系统复杂度管理:分布式系统的运维难度高,阿里通过自动化运维平台和AIOps技术,实现了故障预测与自愈。
- 成本控制:通过资源弹性伸缩和算法优化,阿里在保证性能的将数据处理成本控制在合理范围内。
四、结语
从阿里内部产品可以看出,海量数据处理系统的成功离不开灵活的架构设计和持续的技术创新。随着5G、AI和量子计算的发展,数据处理系统将更加智能、高效和普惠。借鉴阿里的经验,企业和开发者可以构建更适合自身业务的数据处理平台,助力数字化转型。
通过本文的分析,希望读者能深入理解海量数据处理系统的核心要素,并在实际项目中应用这些架构与技术创新。